How to make AI art: DALL-E mini, AI Dungeon, and more
 [ad_1]
[ad_1]
Not all of us have the talent to whip up a piece of art at a moment’s notice. But algorithms using machine learning are learning how to create “AI art” based on text prompts—and you can use them, too. It’s fantastically fun.
Algorithms like DALL-E (and eventually, DALL-E 2), DALL-E mini, Craiyon, Midjourney, Meta’s Make-A-Scene and more are learning how to take publicly available art and learn what makes them art. Or, at least, digest the various elements and style of a photo or artistic work and recombine them into something new. Sure, you can argue whether or not they’re, in fact, “art,” but the creations are unique, original, and compelling.
Simply put, AI art uses a text prompt: something specific like McDonalds at the bottom of the sea, for example, or a bit more generic like the castle of time — the prompt that generated the art at the top of this story. The AI then uses what it’s found on the web and what it knows of the query to custom-create an artistic rendering that matches the description.
Because of the computational requirements of training and using the algorithms, many of the most powerful algorithms are still locked inside beta tests, where only a few lucky participants are able to try them out. One notable exception is DALL-E mini, a public test of the AI that’s available for you to try and is migrating to Craiyon. That’s good news; the DALL-E Mini developers are migrating to Craiyon for trademark reasons, but DALL-E Mini’s popularity swamped the site. But we’ve also found an even better one called Latitude’s Voyage, which can be tried out for free.
DALL-E mini, Craiyon, and its competitors will generate art from just about any idea you have, and the results can be weird, whimsical or anything in between. AI art does have some limitations, though: it’s not great with text, pictures of actual people, and NSFW topics appear to be off limits. And you’ll quickly discover that the computational power and sophistication of the model the art service uses makes a significant difference, which is why Voyage is a superior solution. Most everything else, however, appears to be fair game. The limit is, really, your imagination.

You can use our table of contents to jump directly to the AI art apps, or read on to learn how it all works.
A quick, simple introduction to AI
In general, artificial intelligence works in a fairly simple manner. An algorithm “learns” by being presented with multiple pictures of a cat, say, without being told what characteristics define the cat. It’s up to the algorithm to define these rules, sometimes called “machine learning.” The algorithm is then “tested” with pictures of cats mixed in with photos of dogs, birds, and so on. If the algorithm has been trained enough, it will then be able to recognize “cats” in the real world.
That’s the basics. The algorithms used here, however, are far more sophisticated.
OpenAI, a company co-founded by Elon Musk and others, in 2018 developed GPT (Generative Pre-Trained Transformer), a language model that uses deep learning to produce text that’s similar to what you and I would write. OpenAI has since iterated GPT into its third iteration, GPT-3, whose model was exclusively licensed by Microsoft.
GPT uses what are called “parameters” to define relationships between different types of data, in this case to understand the meaning and context of different words. According to the paper (PDF) that describes the second-generation GPT-2 model, GPT-2 was trained on 8 million documents, or 40GB of text, with 1.5 billion parameters. GPT-3, today’s most powerful version, uses 175 billion parameters and required orders of magnitude more time and compute power to train, according to Wikipedia and the GPT-3 paper.
In terms of horsepower, AI developer Latitude estimated that it required 311 billion teraflops just to train the GPT-3 model, sliced up over various supercomputers around the world. For context, Oak Ridge National Laboratory’s Frontier supercomputer, the most powerful in the world, has a theoretical peak of just 1.1 million teraflops. And an Nvidia GeForce RTX 3080 GPU computes about 30 teraflops, depending on the version.
This means two things. First, a completely PC-bound GPT model is simply infeasible right now. And second, GPT-2 and especially GPT-3 are so sophisticated that the designers were genuinely worried about their ability to fool humans with generated content. Were they right? Well, you can decide for yourself — because the model is available to play with in the real world.
An AI text adventure: AI Dungeon
In 2019, developer Nick Walton released AI Dungeon, an AI-driven text adventure that’s like an open-world Zork — and that’s just scratching the surface. Today, AI Dungeon is available to play on the Web as well as via apps for Windows, Android, and iOS, as part of a company called Latitude.
AI allows you to play a text adventure where you can create the environment entirely from scratch or else use a world that’s been pre-configured by someone else. You’re free to create anything: stories based on fantasy, science fiction, westerns, or whatever you can imagine, and play them through using text prompts. Each text prompt includes three choices: Do something, Say something, or inform the Story with something that happened. Each decision further refines the adventure.
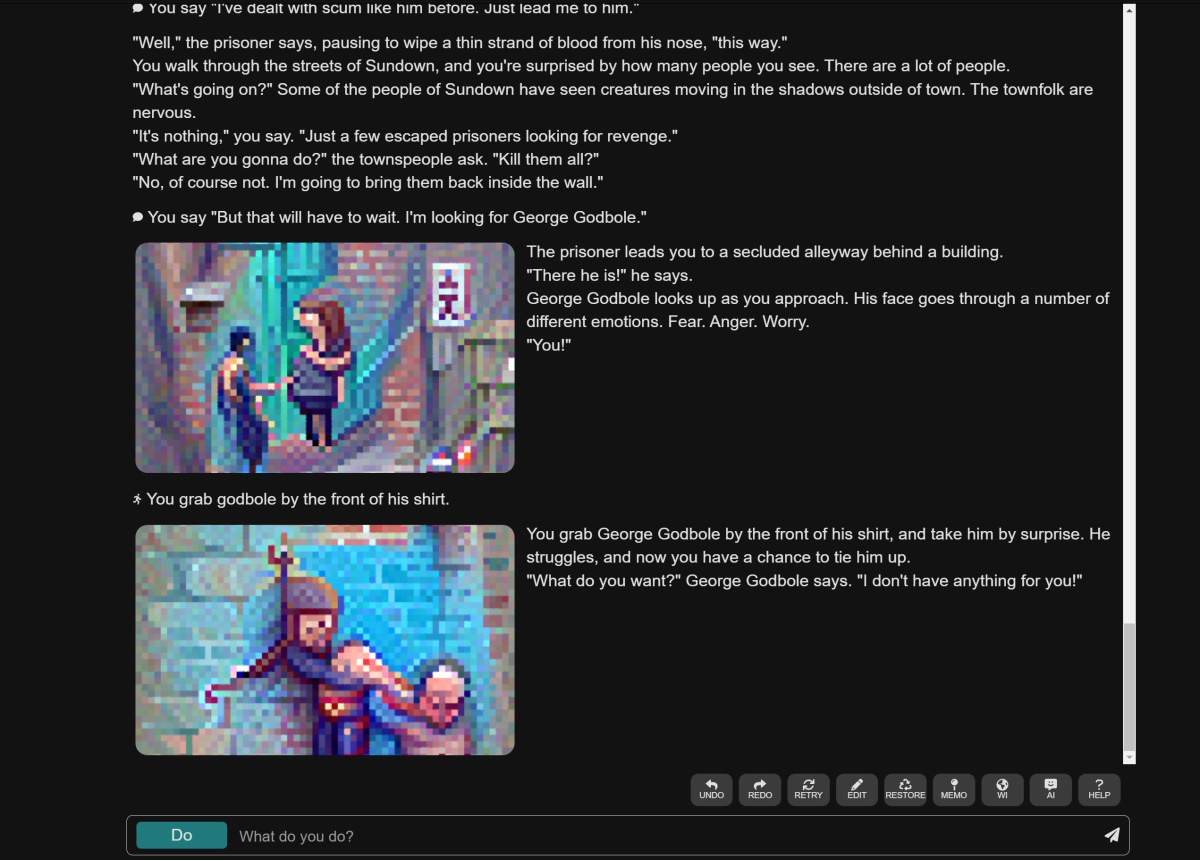
Mark Hachman / IDG
If you’d like, you can play AI Dungeon as a Zork-like adventure, picking a character class, race, and so on. That can work best in a traditional fantasy environment. But you can also create an entirely custom scenario, which can play out in entirely unexpected ways. I created a world in which a Western town sat on the edge of a vast darkness, where monsters roamed, using about three sentences as a seed to describe what the world contained and what my character would be. But my character was almost instantly sucked into a subplot where I rescued a prisoner who was being used by the head of the local thieves’ guild.
AI Dungeon is a “freemium” game: like many mobile games, each “move” is measured, which can be eliminated with a paid plan. In this case, though, it’s justified: there’s a significant server-side cost governing your actions, in terms of CPU resources. (After this story was filed, Latitude issued a blog post announcing an upcoming change in the way you’ll pay for these actions, replacing an “energy” system with actions you can pay by watching video advertising.) You can also choose to pay $14.99 per month for what’s known as “Voyage,” which eliminates the energy limit and also gives you access to two additional perks: “Dragon,” and 20 image generation credits.
While AI Dungeon uses the GPT-2 language models, the paid Vantage version uses a choice of AI models each with different characteristics. The default seems to be Griffin, a 6 billion-parameter AI engine, which generates responses more quickly. (AI Dungeon takes a few seconds or so to generate a response, with longer waits for more complex models.) But you can also opt for Dragon, a much more sophisticated 178-billion-parameter GPT-3 engine, and combine it with Hydra to prioritize responses. You can also tweak the degree of randomness.
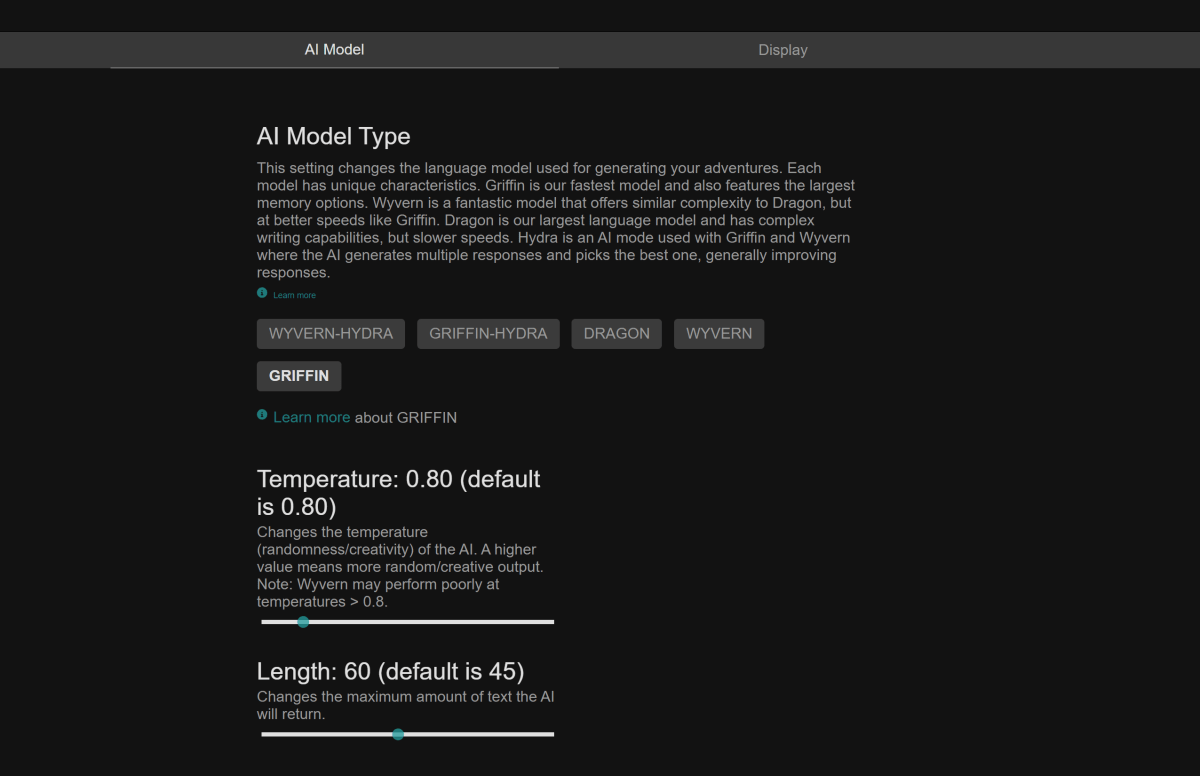
Latitude
While you can play the GPT-2 version of AI Dungeon for free, you may need to use the “Story” prompt to help keep the narrative on track. The Voyage GPT-3 version (which I played in the scenario above) was noticeably better, with a coherent and responsive narrative. My Voyage narrative turned a bit dark (and can go in an NSFW direction, if you adjust the settings) but it was very much worth my time, and yours. You can even save the narrative for yourself, or open it up to the world at large. AI Dungeon (Voyage) will even auto-generate 2D pixel art to illustrate the story as it goes!
Separately, Voyage also includes its own AI-generated art, called AI Art, which you can generate via text prompts. You can choose from one of three engines, however, ranging from PixRay pixel art to the painting-like Disco Diffusion, which will generate your AI art in various styles. (We’ll explore this further a bit later on.)
And that brings us to the topic du jour: AI-generated images, or AI art.
Welcome to the magical world of AI art
AI art uses the GPT model used in AI Dungeon but takes a giant leap forward. Not only does the model understand the relationship between words, but it understands how those words interact with images, too. It’s an improvement that really feels like taking AI Dungeon’s text prompts into an entirely new dimension.

The most visible representation of AI art is DALL-E, a model released by OpenAI in January 2021. The company describes DALL-E as a 12-billion parameter version of GPT-3, which means that, in terms of parameters, it’s somewhere between the GPT-2 and GPT-3. DALL-E 2, released in April, offers “four times greater resolution” than the original DALL-E according to OpenAI, though OpenAI has not released the model publicly. Instead, it’s only available via waitlist to access it in private beta.
According to UC Berkeley graduate student Charlie Snell, DALL-E includes an autoencoder that can correctly design images, and a transformer that understands how the image itself correlates to a textual description. A third piece ranks the images and prioritizes the ones it thinks are the “best.” DALL-E simply works backwards, taking the text prompt and turning it into a coherent, interesting image.

As explained above, DALL-E itself is locked down. But Boris Dayma, a machine learning engineer, created DALL-E Mini to fill the gap, and make it publicly accessible. Dayma’s blog post doesn’t say how complex the model is, though the code is available from the main site (the AI community, Hugging Face) to download yourself — if you have the hardware. Dayma also indicates that there’s a second, more powerful model in the works: DALL-E Mega, “the largest version of DALL-E Mini,” which is still being trained.
DALL-E Mini generates a 3X3 grid of the images it thinks are the best for a given prompt. They’re a mixed bag, and it’s probably good if you don’t go in with high expectations. DALL-E Mini does well with somewhat abstract representations of objects, and can do somewhat poorly with faces and text. In a way, it’s like traveling overseas. If you go looking for “American” food in faraway lands, it might just seem somewhat off. But if you’re willing to try out something wild, you may end up with a result that’s extraordinary.
There’s one drawback though: the traffic. Demand for DALL-E Mini has grown as its popularity has, and you’ll often see a popup that there’s “too much traffic,” and to try again. Your best bet is to either try DALL-E Mini late at night or in the early morning, when traffic is at its lightest. It seems that generating an image takes about two minutes or so, so be prepared to wait, too.
Some DALL-E Mini images are rather good. Some, are, well, kind of horrific. Some are simply bad (and we haven’t shown those here.) You can use our image compare tool, below, to view two images we created.
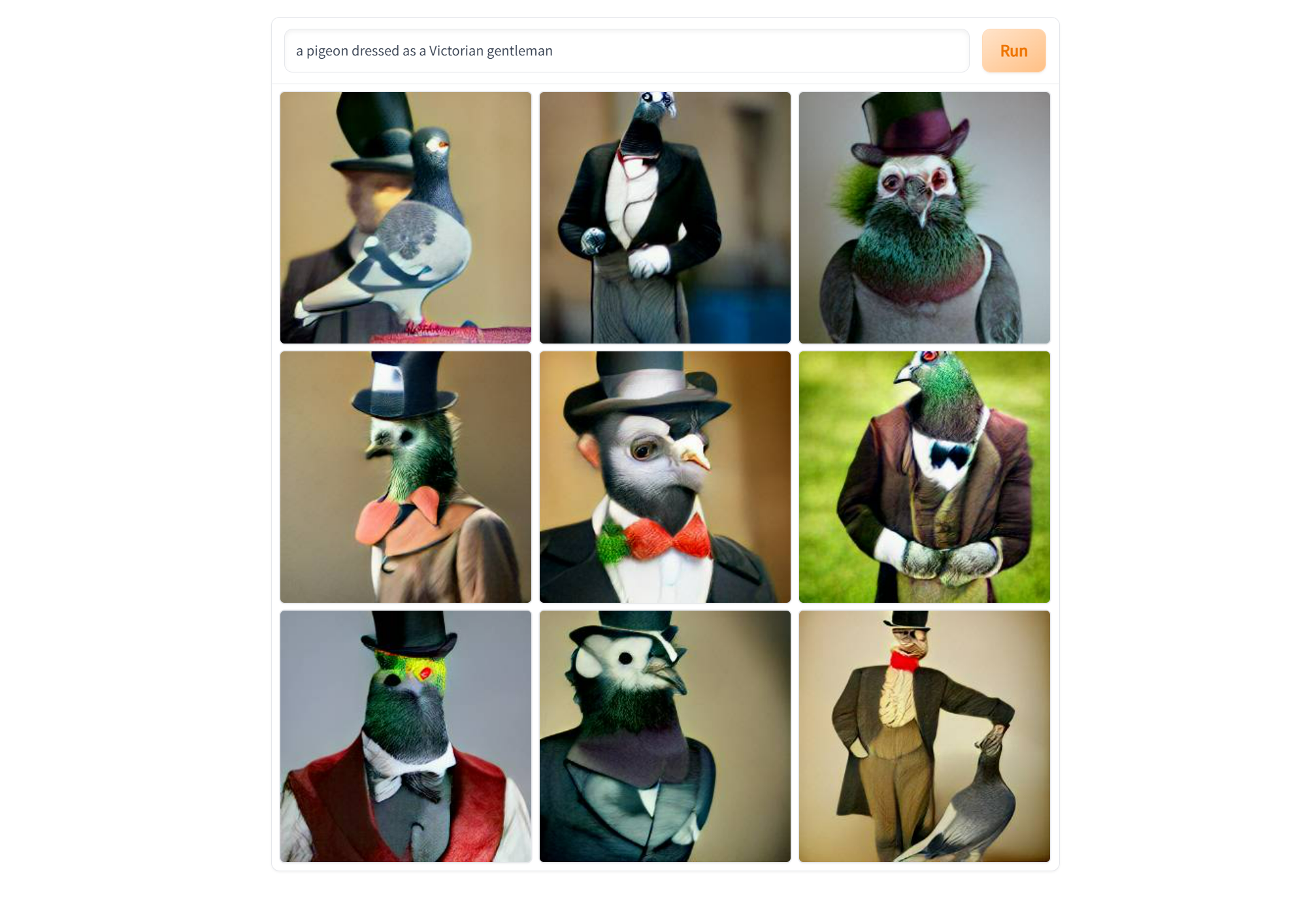

It’s unclear how long DALL-E Mini will remain online, however. The FAQ for Craiyon, another AI art generator, indicates that Dayma began migrating the model over to the new site because of potential confusion between his efforts and OpenAI’s own DALL-E model.
For now, however, you’ll benefit. First, Craiyon appears to be using the DALL-E Mega model, which should theoretically improve the quality of the images shown. I wasn’t really that impressed with my first efforts using the service, but I thought this result was a fun one.
Mark Hachman / IDG
On July 14, Meta debuted Make-A-Scene, a new AI art project that will allow use people to create art using text prompts, as other AI art projects do. The difference here is that users will also be able to sketch out how they want to the overall scene to look. Meta’s example, as outlined in the company’s blog post, gives the example of an AI-generated scene with a bike in it: which way should the bike be facing? Should it be large or small? That’s similar in how other AI art programs can use a piece of art or a photo as a “seed,” but puts more emphasis on the user driving the creative process in Make-A-Scene.
Otherwise, Make-A-Scene looks pretty similar to other AI art projects. It’s limited to “creators” right now, and not yet open to the general public. Some of Make-A-Scene’s art, though, looks pretty good. In part, that’s because it creates 2,048 x 2,048-pixel images.

Meta
The best AI art service right now: Latitude’s Vantage AI Art
So what’s a better bet? Latitude’s Voyage service and its AI Art capability, which offers a free one-week trial. Though you’ll have to subscribe (and enter a credit card) there’s nothing stopping you from using your AI Art credits before the trial expires. (The 20 free image credits renew every month, or you can buy additional credits for 20 credits/$5 for 100 credits/$20.) Even better, there aren’t any traffic limitations, and each AI Art creation comes with a time estimate that’s usually about ten minutes or so. But the higher computational workload (and resulting longer wait) makes for more interesting art.


Again, your results will be a mixed bag, but the various (proprietary?) engines offer a range of styles. I’m partial to the Disco Diffusion engine, which renders images that are more akin to paintings, as shown in our primary image for this article. AI Art also encourages you to submit your text prompt with an artistic style, which I did in another image of a fairgrounds in the style of farmpunk (?) artist Simon Stalenhag. The PixRay pixel art and the VQGAN cartoon aesthetic are also worth trying out. The latter two tend to render much faster. Note that you can make the image size larger than the default, but the algorithm will “charge” you more photo credits if you go too high.
There’s always going to be a degree of artistic interpretation in all of these. While you can try prompting for a “photograph” of a particular scene, you’ll probably be much happier with something that looks more like the creation of an artist rather than a camera.


Neither DALL-E, DALL-E Mini, or Latitude’s Voyage have a monopoly on AI art. Midjourney, a similar service that’s currently in private beta, also has a waitlist that can be applied for. Midjourney’s images are particularly stunning, though it’s not clear how easily you’ll be able to access the service is or what the terms of service are. The “underwater McDonalds” art higher up the page was created on Midjourney, according to the author. The art below was also created using Midjourney, according to the poster.
One big question that remains unanswered: who actually owns this art? If the models were trained on publicly accessible works from the Internet, then modified via AI at the command of a user-generated prompt, it’s unclear if anyone owns it.
AI audio is fun, too
Images aren’t the only source of AI art. In fact, text-to-speech is an excellent way to pass the time and a fun way to even prank your friends. Uberduck.ai is just one of a number of different text-to-speech sites, but site is famous for both its free services (just sign up with a free account, including Google) and the absolute boatload of synthesized voices. All you need to do is type in a passage or a short message, and you can have everyone from Bugs Bunny to Beavis to Batman to Barack Obama read it back — well, a synthesized version of it, anyway. You can even upload your own voice to the site (for $15) if you want to.
And if you want something besides visual art, OpenAI also has another service, called Jukebox. Jukebox serves as an experiment for reproducing the “sound” of a particular band or artist, such as Frank Sinatra or the (Dixie) Chicks, though without the ability to dial up a custom tune. Jukebox is impressive for what it does, but it lacks the “wow!” factor of the other services.
All of these really show off the potential (and pitfalls) of AI art. It’s also true, though, that AI—especially human-like textual constructions created with GPT3—can certainly be used to fool people already deluged with disinformation. All of these examples are designed to be obvious about who and what is constructing the final result, but they don’t have to be. This YouTube video, below, is absolutely not the Queen of England. This is known as a “deepfake,” an AI construct designed to deceive (or entertain, as the case may be.)
Otherwise, however, we really haven’t even scratched the surface of AI-generated video, although it seems like we can use the above examples to suggest some ways forward. Applying AI to a clip from Seinfeld, for example, and replacing George’s voice with that of Bill Gates, for example, doesn’t seem that far-fetched.
[embed]https://www.youtube.com/watch?v=IvY-Abd2FfM[/embed]
What’s more exciting, though, is where this road leads. For now, there’s simply no way to run AI art with any fidelity on a PC. But with continued improvements in the CPU space, the computational power required to process AI art in the server space will continue to drop, with the promise that quality should improve. We don’t consider how many productivity apps either connect to or run in the cloud, and it’s possible that an Adobe, Google, or Microsoft could use their established clouds to facilitate these type of applications for consumers and creators.. Chip companies like AMD, Intel, and Qualcomm have struggled to justify their investments in AI technology in the PC, too. Placing more emphasis on end-user AI applications will help solve that problem.
We’ll close with former president “Bill Clinton,” who has kindly endorsed G3 Box News courtesy of Uberduck.ai, while exemplifying the problems — and potential — of AI.
This story was updated at 9:38 AM on July 15 to add Meta’s Make-A-Scene AI art program.
[ad_2] https://g3box.org/news/tech/how-to-make-ai-art-dall-e-mini-ai-dungeon-and-more/?feed_id=2633&_unique_id=62d1acf4679b3

0 comments:
Post a Comment